Readcube papersを使って「文献管理」をする
研究というものを始めると、多かれ少なかれ先行研究というものを読まなくてはならない。最初の方は先生や先輩に論文を渡されることも多いだろう。慣れない英語がびっしりで、初学者にとっては片手間どころではないはずだ。そして「この論文も君の研究に関連してそうだ」と、面倒見の良い先輩がさらにおかわりをくれるかもしれない。このように、おすすめの論文については教えてもらえるかもしれないが、どうやって読むのか、読んだ論文をどうするのか、について教えてもらえる機会はあまり多くないのではないだろうか?
文献管理とは何か?
読んだ論文をそのままにしておいては、次第に内容を忘れてしまうだろう。多くの研究者は、一度読んだ(ダウンロードした)論文を整理して、いつでもその情報を引き出せるようにしているはずだ。文献管理はその状態を作って維持する作業を指す(と筆者が勝手に定義した)。
文献管理において重要なことは、メモを残して、後で検索できるようにすることだと思う。これらをプリントした論文とメモ用のノートで全て行うのは膨大で大変だけど、「文献管理ソフト」を使えば、パソコン上で簡単にできるようになる。
Readcube papers
筆者がメインで使っている文献管理ソフトである。デスクトップアプリもあるのだが、とっても重かったため、筆者は全てブラウザ上で使っている。他の文献管理ソフトと同じように、pdfを直接アップロードしたり、Chromeの拡張機能を使ってワンクリックで論文を取り込んだりすることができる。読み込んだpdfは専用のビューアーで閲覧することができて、左のサムネールにreferenceを表示させたり、ページや目次を表示させることもできる。サプリのファイルも自動でダウンロードしてくれる。(してくれないときもあるが、そのときは手動で簡単にできる。)その論文を引用している論文もすぐに閲覧できる。
メモを残す
他の文献管理ソフトも同様だろうが、Readcube papersは豊富なメモ機能がついている。HighlightやUnderline、Sticky noteはもちろん、Draw pathを使って自由に線を描くこともできる。iPadなどのタブレット端末を持っていれば、Draw pathで手書き感覚でメモを取ることもできるだろう。また、それぞれの装飾機能について多種の色分けもできる。
メモはとにかく気がついたところに書き込んでいけば良いと思う。使う色などのルールを作ると後で読み返すときに便利かもしれない。筆者の場合、紫マーカーには疑問点を、緑マーカーには英単語の意味を載せている。他にも黄色マーカーや赤の下線を使って、大事だと思う箇所をハイライトしている。Sticky noteとDraw pathを使って、図にツッコミを入れたりもしている。 ただし、あまり複雑なルールを作らないことも大事だと思っていて、複雑なルールのせいでメモを書き込むことが面倒になってしまっては本末転倒である。まずは黄色マーカーだけでハイライトしていくだけでも十分かもしれない。

検索する
これまた他の文献管理ソフトと同様に、Readcube papersにもタグ付けやフォルダによる階層型管理ができる。だけど個人的にはほとんど使ってない。使い始めの頃は一生懸命タグを付けていたんだけど、タグが細かくなりすぎて、一個一個の論文に何を割り当てるかを考えるのが徐々に面倒くさくなってしまったのだ。フォルダ分けも同じ理由でほとんど使っていない。ただし、論文のreference listを作るときだけはそれ専用のフォルダを作って、wordのアドオンからアクセスしやすいようにしている。
探したい論文があるときは検索機能を使って見つけている。Readcube papersの検索機能はなかなか有能で、検索窓にキーワードを入力すると、要旨や本文、自分の書いたメモの内容まで含めて探してくれる。検索窓に特定の書式を入力すれば、著者や発行年、ジャーナル名を指定して検索もできる。例えば、2024年の論文を探したいときは「year:2024」を入れれば良い。1993年以前の論文を探したいときは「year:[* TO 1993]」を入れれば良い。(*はワイルド的な意味らしいので、位置をTOの後にすれば、「以後」になる。)筆者の経験上、読んだ論文はこれでほぼ絶対に見つかる。また、アプリに表示されるリストの情報にLast Readというのがあって、これを降順に設定しておけば最近読んだ論文が上に表示されるようになる。これも地味に便利。(比較的最近できるようになって感動した。)


終わりに
というわけで、ほんのざっくり自己流の文献管理について書いてみた。「読んだ論文をどうするのか」という導入から始めたけど、実はタイトルだけ見て気になった論文とか、他人から薦められた論文とかもどしどし入れている。その際も、少しだけ補足情報(「XXさんにもらった」とか)を入れておくと、後で取り出しやすくなるかもしれない。
文献管理はほとんどの人が自己流でやってるはずで、もっと楽で効率の良い方法もあるのだろうと思ってる。そういうtipsをもっと聞いてみたいといつも思ってる。
Readcube papersについて話したけど、きっと他のアプリでも同じようなことができるはずだ。筆者は惰性で使い続けて10年目に突入してしまったのだが、あまりに依存してしまっているせいで、Evernoteのようにいつかサービスが打ち切られたときどうしたら良いんだろうという不安はある。
情報理論による因果推論
このブログも3日坊主どころか、たった1つの投稿をしてから一年半以上も放置してしまった。
はじめに
この記事では、情報量の定義の説明から始めて、時系列データの因果推論で用いられる移動エントロピー(Transfer Entropy)の考え方を解説しようとしている。移動エントロピーという言葉を聞いたことあるけど、どうやって計算するの?くらいの期待には応えられるような解説になっているといいなと思っている。さらに、移動エントロピーの考え方をより一般化したCausation entropyについても紹介する。これについては、パッと検索しても日本語の説明が見つからなかったので、少しだけこの記事の意義になるのではと期待している。ただし、その信憑性については筆者の力量の範囲内であることを了承していただきたい。参考文献も最後につけるので、興味を持った場合は、ぜひ自分で確認してほしい。
情報量
ある出来事x(確率:p(x))についての情報量:I(x)は以下のように定義される。
確率の逆数に底が2の対数をとる。定義上、xの確率が低いほど大きくなる。確実なこと(確率が高いこと)を知るよりも、不確実なこと(確率が低いこと)を知る方が情報量は大きいという意味。
対数の底を2としているのは、慣習的に情報量の単位をbitで考えることが多いため。以降の式では底の値を省略する。
また、わざわざ対数を取るのは、確率の結合を和で考えることができるから。(統計を学んでいると対数変換はよく出てくる。)
エントロピー
エントロピーは情報量の期待値として定義される。ゆえに「平均情報量」と呼ばれることもある。
と書いて、集合Xに含まれる事象xについてという意味になる。(以降の式では単にxと省略して書く)
ただしである。
例えばサイコロを投げるとき、出る目はで、イカサマのないサイコロならば、それぞれの確率は1/6である。
そのエントロピーを実際に計算してみると
となる。
これは、2つ以上の確率変数についても同様に定義できて、このとき結合エントロピーと呼ばれる。
相互情報量
相互情報量I(X;Y)は2つの確率変数の相互依存の尺度を表す。(とwikipediaが言っていた)
急にごちゃごちゃした式が出てきたが、展開してみるとその意味が分かりやすくなるかもしれない。
これは、対数の中の分数を引き算に分解した、ということである。
第一項は結合エントロピーであることがわかる。(ただし符号は負であることに注意)
第二項についてさらに整理すると
第三項についても同様に
したがって、式を整理すると
となることがわかる。
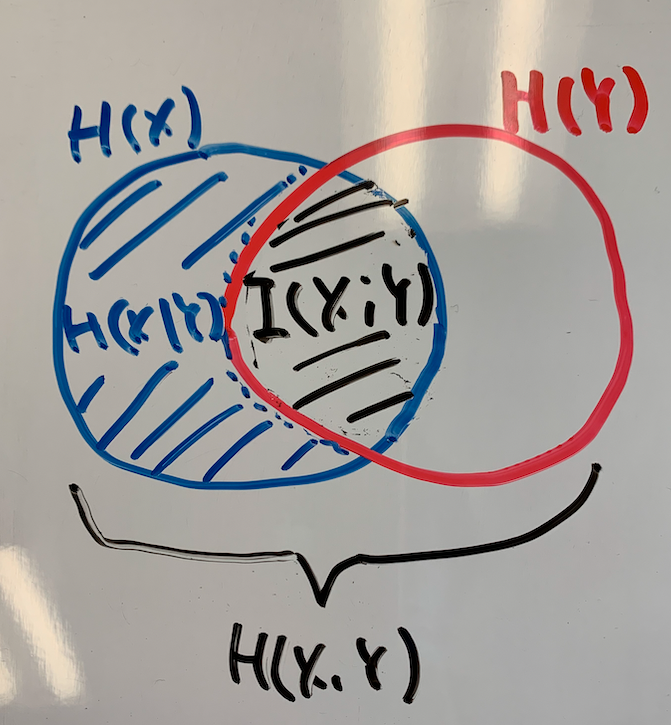
このことから、これまで登場してきたエントロピーと相互情報量の関係は以下のようなベン図で表現できる。

このベン図と数式の対応を理解することが、情報理論の勉強ではそこそこ重要であると思われるので、意識して慣れるようにした方がいいかもしれない。
ちなみに、XとYが独立のとき、つまりのとき、
となる。これはベン図からも明らかだが、数式からみてもlogの中身が1になることがわかる。
条件付きエントロピー
YがわかっているときのXのエントロピーは以下のように定義される。
これも相互情報量のときと同じように展開すると、
と表すことができ、ベン図で表すところのちょうどH(X)からH(Y)の部分との重なりを取り除いた部分である。
つまり、式変形については割愛するが、
も成り立つ。
以上までは、シンプルな理解のために確率変数は2つまでしか出てこなかったが、その個数の制限はもちろんない。試しに3つに拡張したものをベン図で表してみる。
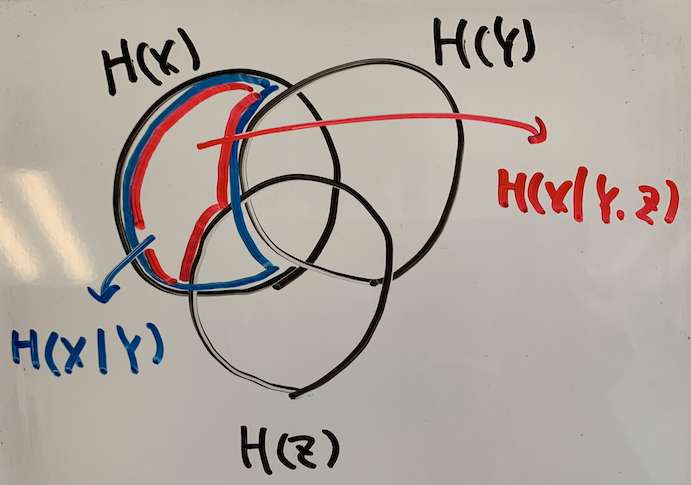
H(X|Y)とH(X|Y,Z)を比べると、(ZがXと独立でない限り)H(X|Y,Z)はH(X|Y)に比べて小さくなる。
つまり、Zを知ることでXのエントロピーはさらに減少したと言える。
さて、ここまでで移動エントロピーを理解するための材料は揃ったと言える。移動エントロピーは結局のところ、ここまでの概念をほんの少し応用した指標に過ぎないのだ。
移動エントロピー
YからXへの情報の流れ、つまり移動エントロピーは次のように定義される。
右辺の第一項が過去のXがわかっているときの現在のXについての条件付きエントロピー、第二項は過去のXとYの両方がわかっているときの現在のXについての条件付きエントロピーである。
その差をとって、Yの過去がXに与える影響を情報量として測る、という意味である。
上の式は一つ手前の時点のみを参照しているが、この基本形は実は先ほど出した3つの変数の条件付きエントロピーを計算することができれば、求まることが想像できると思う。
ここまでは実はそんなに難しくないのだ。(と言っても、私の場合、ここまで理解するのにそこそこの時間を費やした)
ただし、一つ手前の1時点のみを参照するのはあまり現実的ではないので、もっと長いスパンの「履歴」を参照することもできる一般形が以下の式である。
τはいくつの時点前までを参照するかの数である、つまり、である。Yについても同様である。
移動エントロピーで大事な概念は、「方向」が存在することである。
つまり一般には成り立たない。
さらに向きがあるということは、が0よりも大きければ、YからXへの情報の流れがあると言うことができ、時系列の観点から「因果」があると推論することができるとされている。
Causation Entropy
移動エントロピーでは、情報の流れの向きを考慮しているが、2つの時系列過程における情報の流れが直接的なのか間接的なのかについては、実は十分に評価できない。
例えばX, Y, Zという3つの過程があって、ZからXへの移動エントロピーを測ったとする。しかし、それがYを経由した間接的な流れ(Z→Y→X)の可能性があるが、それを評価できないということである。
研究者が得られる時系列のデータはいつも2つとは限らないだろう。実際には多様な時系列のデータが同時に取れてきて、それらは互いに複雑なネットワークのような関係を持つことがしばしばであるはず。
そこで最近登場したのが、ネットワークの中の情報の流れを測るCausation entropyである。今回のケースの場合、ZからXへのCausation entropyは次のように定義される。
右辺が意味するところは、Z以外の全ての過程の過去を知っているときのエントロピーから、Zも含む全ての過程の過去を知っているときのエントロピーを差し引いたものである。これによってZがXに与える情報の流れを測るということである。
さらに一般化した定義が以下のように表現される。
ここでは、という複数の要素をもつネットワークがあったときの、
から
への情報の流れを測っている。右辺の第一項は
以外の全ての要素の過去を知っているときのエントロピーで、第二項は
を含む全ての要素の過去を知っているときのエントロピーである。
これは実は移動エントロピーをより一般化したものとも言える。というのは、ネットワークの要素を2つとした場合、そのまんま移動エントロピーの式になるからである。
最後に
ここまで読んでもらえたら、とりあえず式変形を追えて、なんとなくどうやって計算しているのかはわかってもらえたかもしれない。つまるところ、複数の変数の条件付きエントロピーが計算できれば、これらは計算できるはずなのである。ただし、現在の筆者はその段階で色々と苦戦している。
色々理由はあるのだが、まずCausation entropyを楽ちんに計算できるようなパッケージは今のところ見当たらない。そこで、条件付きエントロピーを計算すれば良いと思いきや、ほとんどのパッケージは2つの変数までである。移動エントロピーやCausation entropyを計算する際、どうしても多数の変数の条件付きエントロピーを計算する必要がある。
じゃぁ、自分でコードするしか、というと筆者のプログラミング能力ではちょっと難しいように思える。プログラミングというか、複数の結合確率分布をどう扱うか、というような理解不足によるところも大きい気がする。
というわけで、どなたか識者の方の目に届いて、何かアドバイスを頂けたらと思って、キーボードを置くことにする。
また気が向くそのときまで。
参考文献
特にCausation entropyあたりに関するものだけ置いておく。
Sun & Bollt (2014). Causation entropy identifies indirect influences, dominance of neighbors and anticipatory couplings. Physica D
Causation entropyを最初に発表した論文
Pilkiewicz et al. (2020). Decoding collective communications using information theory tools. J R Soc Interface
アリの集団行動モデルを用いながら、Causation entropyを含めた情報理論ツールを使った解析についてを解説している総説
【論文紹介】ネズミの会話を覗く
ハムスターや小魚などの小動物を複数で飼育したことがある人ならば誰でも,「彼らは何を話しているのだろう?」という感想を持ったことがあると思う.今日紹介する論文は,そんな純粋な疑問への挑戦と言えるかもしれない.
Nature Neuroscienceに掲載されてはいるが,神経活動の記録や遺伝学的操作も行われていない,純粋な行動実験のみの論文である.まぁ,雑誌の興味が手法を限定する必要もないのだから,特に問題にはならないけど珍しい類であると思う.
この論文が何を明らかにしたのか.著者らは雌雄2匹ずつのマウスを同じケージに入れてその行動と発声を観察し,(1)雄マウスが発声する超音波には種類(レパートリー)がある,(2)発声するレパートリーは行動の種類(攻撃する・逃げるなど)によって異なる,(3)発声は社会的相互作用(social interaction)をとっている相手の行動を変えうる,ということを発見した.
これだけ言うと,「そんなのコミュニケーションをとっているのだから当たり前なんで?」,と思えるかもしれない.だけど,この当たり前の実態を観察して記載するのは実はかなり困難だった.
複数個体の動物のコミュニケーションを解析するためには,誰がどこで何をしているときに何を言ったのか,を全て観察できなければならない.この研究グループは実は先行研究で「誰が」を知る方法を確立している.
どんな方法かざっくり言うと,ケージにマイクをたくさん置くことでその音源を正確に当てるようにしたと言うことらしい.(他にも計算方法に工夫があるらしいが,そこはまだ読めていない)
「何をしているときか」はどうやって決めるのかというと,これもすでにJanelia Farmの研究グループが開発した行動自動分類ソフト『JAABA』を使用して決めている.
「何を言ったのか」については,今回の論文で新しい手法を用いているらしい.基本的な戦略はマウスの発声をグループ分けするということだ.そのためにk-means法を応用したような感じの方法を使っているようだが,k-meansというと最初にクラスターの数を予め指定しなければならないため,なんか他により良い方法があるような気もする.とにかく,グループ分けすることで,発声信号の違いを使い分けているかどうかを定量的に調べることができるようになる.
「どこで」というのは言わずもがな,ビデオを見れば良いということだ.
このようないろいろな新しい手法を併せて,今回の結果が得られたということのようだ.
神経科学の立場からすれば,じゃぁこういったコミュニケーションをしているときに,脳はどのように働いているのか,ということを知りたくなるだろう.お互いにコミュニケーションをとっている間に神経活動を記録するという実験はすでに最近発表されている.
この記録できた神経活動を,発声となんらか関連付けられたら面白そうだな,と思う.